广告投放系统简介
本文主要介绍了广告算法入门的一些基础知识。主要介绍了广告投放漏斗的几个部分承担的功能、各自的特点以及常见的一些算法。
所谓搜广推是一家,本质上来说,[推荐/广告]和[搜索]的所使用的技术都是非常类似的,不同的是搜索有个很强的query特征(用户自己输入的信息,比如你去淘宝上面搜索的商品名称),而推荐或者广告的缺少query特征,只能从用户特征/商品特征/上下文特征/历史行为特征中对用户的兴趣进行挖掘。 广告系统按照漏斗的形式,从数百数千万候选广告中,对用户的每一刷筛选出几十个广告,然后发送给用户。
广告投放系统的漏斗大致可以分为 [定向/召回/粗排/精排/混排] 5个部分,有些系统可能没有混排,或者把粗排精排放在一起(当系统候选规模较小的时候)。
1. 定向
广告主设定广告面向的人群对象筛选条件,结合业务上对每个用户可投广告的控制(流控、频控、其它规则)对广告全集进行筛选。
一般受制于latency(系统耗时),我们选择定向与召回结果取交集送粗排。
定向的基本检索方式为建立倒排索引,map<filed, map<value, bitmap>
>。 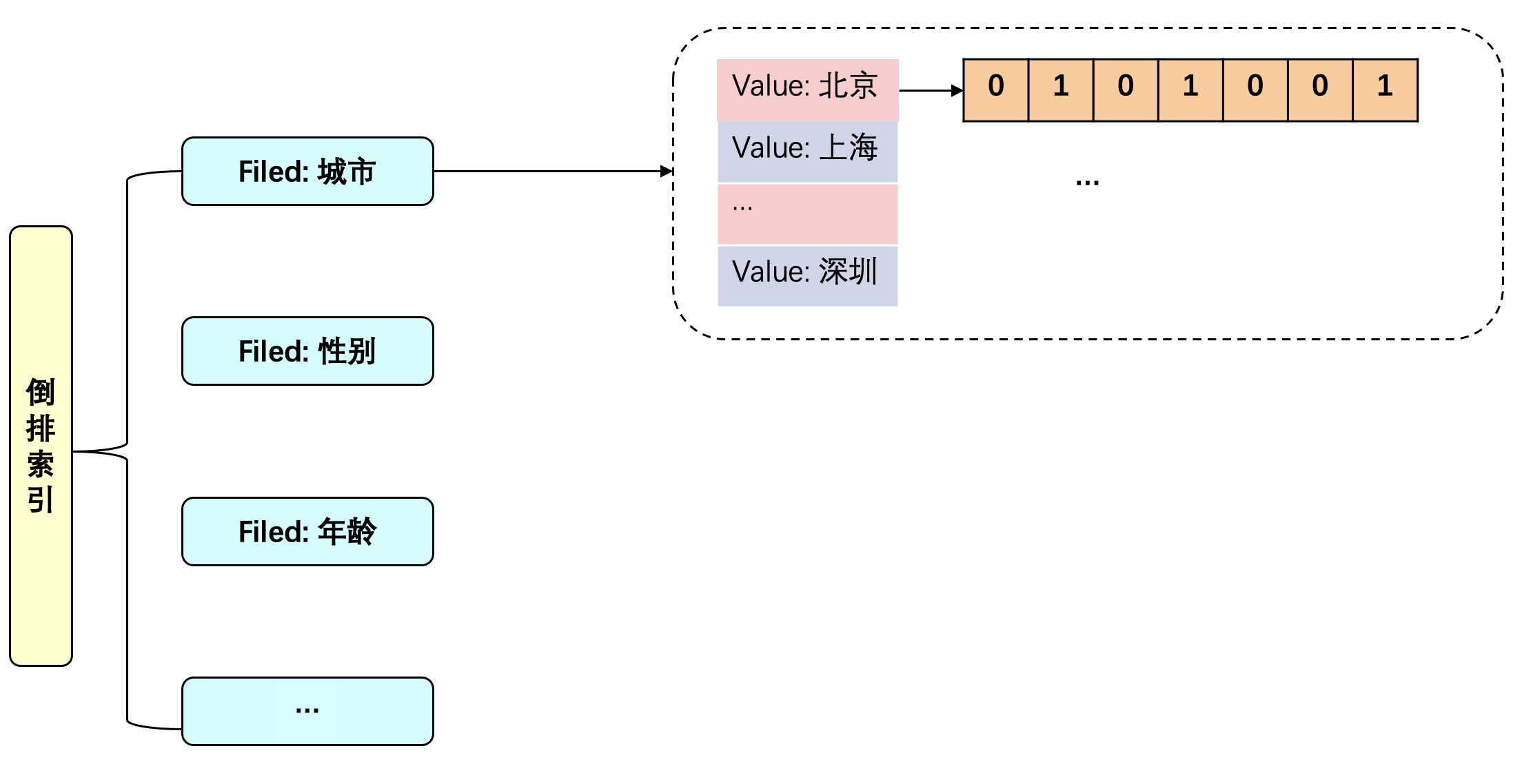 bitmap中的每一个bit,对应一个广告id,几个规则索引一起按位取交集,得到定向的结果candidate广告。
bitmap中的每一个bit,对应一个广告id,几个规则索引一起按位取交集,得到定向的结果candidate广告。
[全量] vs [增量]
- 全量指的是过去较长时间里面的旧索引
- 增量指的是全天24小时里面新增的一些广告
[频控] vs [流控]
- 频控从用户的角度出发,考虑用户的一些浏览历史,然后过滤掉本次不适合对用户展示的广告。
- 流控从广告商的角度出发,既需要消耗广告商的budget,又需要避免广告计划的超投超预算。
- 频控流控需要取交集
存在问题:大量召回的结果可能被定向过滤,严重的时候无效召回的quota会挤占有效召回的quota,造成系统效率低下。 > 拟解决方案:考虑将定向的条件编码为特征向量,参与向量化召回。
2. 召回
召回和粗排的意义都在于缩小候选广告的一些规模,减小精排的计算压力。
- 召回的建模方式:包括对齐精排top1目标的LTR(learning to rank),对齐混排结果send的目标的R2S(recall to send),以及分开建模的方式CTR*CVR等等。
- 召回向量的检索方式:有全局暴力检索(量化方式,将float16映射到int8,int4表示等等);近似检索方式ANN近似最近邻算法(HNSW(图检索),FBT(树+聚类),GuideHNSW(K-means聚类,然后召回topk个cluster),以及Deep retrieval(端到端的图算法,Ad学习出来一个path,可以理解为ad的聚类,path和ad是多对多的关系,然后召回的时候根据user embedding使用beam search找出用户偏好的path,召回path上面的广告))
- 向量相似性的度量:NN,內积,cosine距离等等
[多路召回]
为了保证覆盖率,召回一般都采用多路召回,比如Deep retrieval + 保量召回 + 素材召回 + rankuser(冷启动广告召回) + IVF量化/LTR(ANN召回) 多路召回的结果使用snake merge算法进行保序合并。